Web crawlers, web spiders hay bot công cụ tìm kiếm là những khái niệm không mấy xa lạ với marketer hoặc thậm chí là người dùng web.
Những gì chúng ta thường nghe về web crawlers là nhiệm vụ duyệt website trên mạng World Wide Web một cách có hệ thống, giúp thu thập thông tin của những trang web đó về cho công cụ tìm kiếm.
Tuy nhiên, cách thức hoạt động của web spiders ra sao và có tầm ảnh hưởng như thế nào đến quá trình SEO không phải là điều mà ai cũng biết.
Để tìm câu trả lời cho các vấn đề kể trên, hãy cùng tôi tìm hiểu bài viết dưới đây nhé!
Crawl là gì?
Crawl là cào dữ liệu (Crawl Data) là một thuật ngữ không còn mới trong Marketing, và SEO. Vì Crawl là kỹ thuật mà các con robots của các công cụ tìm kiếm sử dụng như: Google, Bing Yahoo…

Công việc chính của crawl là thu thập dữ liệu từ một trang bất kỳ. Rồi tiến hành phân tích mã nguồn HTML để đọc dữ liệu. Và lọc ra theo yêu cầu người dùng hoặc dữ liệu mà Search Engine yêu cầu.
Web Crawler là gì?
Trình thu thập thông tin web (Web crawlers), Spider hay bot công cụ tìm kiếm có nhiệm vụ tải xuống và Index toàn bộ phần Content từ khắp các nơi trên Internet.

Từ crawl (thu thập thông tin) trong cụm “Web crawlers” là thuật ngữ kỹ thuật dùng để chỉ quá trình tự động truy cập website và lấy dữ liệu thông qua một chương trình phần mềm.
Mục tiêu của bot là tìm hiểu (hầu hết) mọi trang trên website xem chúng nói về điều gì; từ đó, xem xét truy xuất thông tin khi cần thiết. Các bot này hầu như luôn được vận hành bởi các công cụ tìm kiếm.
Bằng cách áp dụng thuật toán tìm kiếm cho dữ liệu được thu thập bởi web crawlers, công cụ tìm kiếm có thể cung cấp các liên kết có liên quan để đáp ứng các truy vấn tìm kiếm của người dùng. Sau đó, tạo danh sách các trang web cần hiển thị sau khi người dùng nhập từ khóa vào thanh tìm kiếm của Google hoặc Bing (hoặc một công cụ tìm kiếm khác).
Tuy nhiên, thông tin trên Internet lại vô cùng rộng lớn, khiến người đọc khó mà biết được liệu tất cả thông tin cần thiết đã được index đúng cách hay chưa?
Liệu có thông tin nào bị bỏ qua không?
Vì thế, để có thể cung cấp đầy đủ thông tin cần thiết, bot trình thu thập thông tin web sẽ bắt đầu với một tập hợp các trang web phổ biến trước; sau đó, lần theo các siêu liên kết từ các trang này đến các trang khác và đến cả các trang bổ sung, v.v.
Trên thực tế, không có con số chính xác bao nhiêu % các website hiển thị trên Internet thực sự được thu thập thông tin bởi các bot của công cụ tìm kiếm. Một số nguồn ước tính rằng chỉ 40-70%, tương ứng với hàng tỷ website trên Internet được index cho mục tìm kiếm.
Cách bot công cụ tìm kiếm crawl website
Internet không ngừng thay đổi và mở rộng. Vì không thể biết tổng số website có trên Internet, web crawlers bắt đầu từ một danh sách các URL đã biết. Trước tiên, chúng thu thập dữ liệu webpage tại các URL đó. Từ các page này, chúng sẽ tìm thấy các siêu liên kết đến nhiều URL khác và thêm các liên kết mới tìm được vào danh sách các trang cần thu thập thông tin tiếp theo.
Với số lượng lớn các website trên Internet có thể được lập chỉ mục để tìm kiếm, quá trình này có thể diễn ra gần như vô thời hạn. Tuy nhiên, web crawler sẽ tuân theo một số chính sách nhất định giúp nó có nhiều lựa chọn hơn về việc nên thu thập dữ liệu trang nào, trình tự thu thập thông tin ra sao và tần suất thu thập lại thông tin để kiểm tra cập nhật nội dung.
Tầm quan trọng tương đối của mỗi trang web: Hầu hết các web crawlers không thu thập toàn bộ thông tin có sẵn công khai trên Internet và không nhằm bất kỳ mục đích gì; thay vào đó, chúng quyết định trang nào sẽ thu thập dữ liệu đầu tiên dựa trên số lượng các trang khác liên kết đến trang đó, lượng khách truy cập mà trang đó nhận được và các yếu tố khác biểu thị khả năng cung cấp thông tin quan trọng của trang.
Lý do đơn giản là nếu website được nhiều trang web khác trích dẫn và có nhiều khách truy cập thì chứng tỏ nó có khả năng chứa thông tin chất lượng cao, có thẩm quyền. Vì vậy, công cụ tìm kiếm dễ gì không index ngay.
Revisiting webpages:
Là quá trình mà web crawlers truy cập lại các trang theo định kỳ để index các phần content mới nhất bởi content trên Web liên tục được cập nhật, xóa hoặc di chuyển đến các vị trí mới..
Yêu cầu về robots.txt:
Web crawlers cũng quyết định những trang nào sẽ được thu thập thông tin dựa trên giao thức robots.txt (còn được gọi là robot giao thức loại trừ). Trước khi thu thập thông tin một trang web, chúng sẽ kiểm tra tệp robots.txt do máy chủ web của trang đó lưu trữ.
Tệp robots.txt là một tệp văn bản chỉ định các quy tắc cho bất kỳ bot nào truy cập vào trang web hoặc ứng dụng được lưu trữ. Các quy tắc này xác định các trang mà bot có thể thu thập thông tin và các liên kết nào mà chúng có thể theo dõi.
Tất cả các yếu tố này có trọng số khác nhau tùy vào các thuật toán độc quyền mà mỗi công cụ tìm kiếm tự xây dựng cho các spider bots của họ. web crawlers từ các công cụ tìm kiếm khác nhau sẽ hoạt động hơi khác nhau, mặc dù mục tiêu cuối cùng là giống nhau: cùng tải xuống và index nội dung từ các trang web.
Tại sao Web Crawlers được gọi là ‘spiders’?
Internet, hoặc ít nhất là phần mà hầu hết người dùng truy cập, còn được gọi là World Wide Web – trên thực tế, đó là nơi xuất phát phần “www” của hầu hết các URL trang web.
Việc gọi các bot của công cụ tìm kiếm là “spiders” là điều hoàn toàn tự nhiên, bởi vì chúng thu thập dữ liệu trên khắp các trang Web, giống như những con nhện bò trên mạng nhện.
Các yếu tố ảnh hưởng đến Web Crawler là gì?
Tổng cộng các website đang hoạt động hiện nay lên đến hàng triệu trên toàn thế giới. Mọi người liệu có đang hài lòng về tỷ lệ crawl và index hiện tại không? Vẫn có rất nhiều người thắc mắc tại sao bài viết của họ lại không được index.
Vậy hãy cùng tìm hiểu các yếu tố chính, đóng vai trò quan trọng trong việc crawl và index của Google.
Domain
Google Panda ra đời để đánh giá tên miền, thì tầm quan trọng của tên miền được cải thiện đáng kể. Các tên miền bao gồm từ khóa chính được đánh giá tốt, website khi được crawl tốt cũng sẽ có thứ hạng tốt trên kết quả tìm kiếm.
Backlinks
Các backlinks chất lượng giúp website thân thiện với công cụ tìm kiếm, được tin cậy và chất lượng hơn. Nếu nội dung của bạn tốt, thứ hạng của website cũng tốt, nhưng lại không có bất kỳ backlinks nào thì công cụ tìm kiếm sẽ giả định nội dung website của bạn không chất lượng, kém.
Internal Links
Trái ngược với backlinks, Internal Links là các links dẫn đến các bài viết nội bộ website. Đây là yếu tố bắt buộc cần có khi làm SEO, không chỉ có lợi cho SEO mà còn giảm tỷ lệ thoát website, tăng thời gian onsite của người dùng, điều hướng truy cập của người dùng đến các trang khác trong website của bạn.
XML Sitemap
Sitemap là điều cần thiết của mọi website và rất thuận tiện khi bạn có thể tạo nó một cách tự động. Điều này giúp Google index bài viết mới hoặc những thay đổi, cập nhật nhanh nhất có thể.
Duplicate Content
Trùng lặp nội dung sẽ bị Google block, lỗi này có thể khiến website của bạn bị phạt và biến mất khỏi kết quả tìm kiếm. Khắc phục các lỗi chuyển hướng 301 và 404 để được crawling và SEO tốt hơn.
URL Canonical
Tạo URL thân thiện với SEO cho mỗi trang trên website, điều này hỗ trợ SEO đồng thời hỗ trợ website.
Meta Tags
Thêm meta tags độc đáo, không trùng nhau để đảm bảo website có thứ hạng cao trong công cụ tìm kiếm.
Bots crawl website có nên được truy cập các thuộc tính web không?
Web crawler bots có nên được truy cập các thuộc tính web không còn phụ thuộc vào thuộc tính web đó là gì cùng một số yếu tố khác kèm theo.
Sở dĩ web crawlers yêu cầu nguồn từ máy chủ là để lấy cơ sở index nội dung – chúng đưa ra các yêu cầu mà máy chủ cần phản hồi, chẳng hạn như thông báo khi có người dùng truy cập website hoặc các bot khác truy cập vào website.
Tùy thuộc vào số lượng nội dung trên mỗi trang hoặc số lượng trang trên website mà các nhà điều hành trang web cân nhắc có nên index các tìm kiếm quá thường xuyên không, vì index quá nhiều có thể làm hỏng máy chủ, tăng chi phí băng thông hoặc cả hai.
Ngoài ra, các nhà phát triển web hoặc công ty có thể không muốn hiển thị một số website nào đó trừ khi người dùng đã được cung cấp link đến trang.
#Ví dụ:
Điển hình cho trường hợp là khi các doanh nghiệp tạo một landing page dành riêng cho các chiến dịch marketing, nhưng họ không muốn bất kỳ ai không nằm trong danh sách đối tượng mục tiêu truy cập vào trang nhằm điều chỉnh thông điệp hoặc đo lường chính xác hiệu suất của trang.
Trong những trường hợp như vậy, doanh nghiệp có thể thêm thẻ “no index” vào trang landing page để nó không hiển thị trong kết quả của công cụ tìm kiếm. Họ cũng có thể thêm thẻ “disallow” trong trang hoặc trong tệp robots.txt để spiders của công cụ tìm kiếm sẽ không thu thập thông tin trang đó.
Chủ sở hữu web cũng không muốn web crawlers thu thập thông tin một phần hoặc tất cả các trang web của họ vì nhiều lý do khác.
Ví dụ: một website cung cấp cho người dùng khả năng tìm kiếm trong trang web có thể muốn chặn các trang kết quả tìm kiếm, vì những trang này không hữu ích cho hầu hết người dùng. Các trang được tạo tự động khác chỉ hữu ích cho một người dùng hoặc một số người dùng cụ thể cũng sẽ bị chặn.
Sự khác biệt giữa Web Crawling và Web Scraping
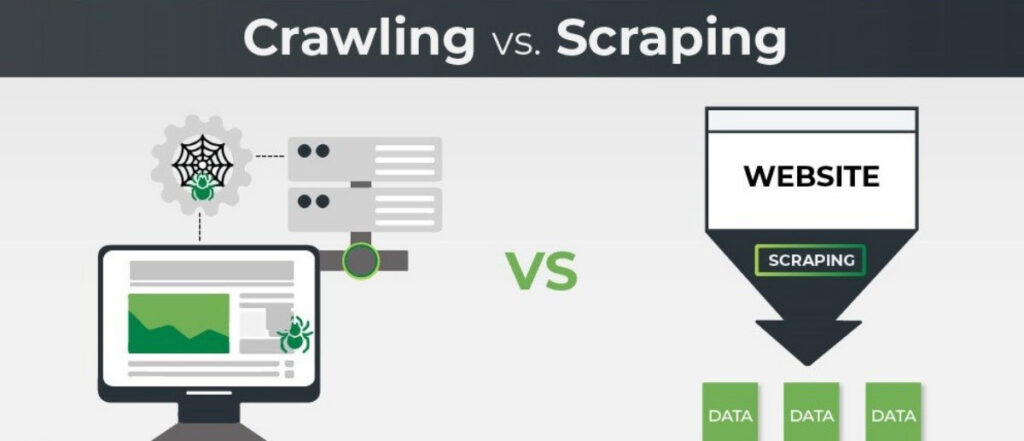
Data scraping, web scraping hoặc content scraping là hành động một bot tải xuống nội dung trên một trang web mà không được cho phép bởi chủ website, thường với mục đích sử dụng nội dung đó cho mục đích xấu.
Web scraping thường được target nhiều hơn web crawling. Web scrapers có thể chỉ theo dõi một số trang websites cụ thể, trong khi web crawlers sẽ tiếp tục theo dõi các liên kết và thu thập thông tin các trang liên tục.
Bên cạnh đó, web scraper bots có thể qua mặt máy chủ dễ dàng, trong khi web crawlers, đặc biệt là từ các công cụ tìm kiếm lớn, sẽ tuân theo tệp robots.txt và gia hạn các yêu cầu của chúng để không đánh lừa máy chủ web.
“Bọ” crawl website ảnh hưởng thế nào đến SEO?
SEO là quá trình chuẩn bị content cho trang, góp phần để trang được index và hiển thị trong danh sách kết quả của các công tìm kiếm.
Nếu spider bot không thu thập dữ liệu một website, thì hiển nhiên nó sẽ không thể được index và không hiển thị trong kết quả tìm kiếm.
Vì lý do này, nếu chủ sở hữu website muốn nhận được lưu lượng truy cập không phải trả tiền từ kết quả tìm kiếm, họ không nên chặn hoạt động của bot crawlers.
Những chương trình thu thập thông tin web nào đang hoạt động trên Internet?
Các bot từ các công cụ tìm kiếm chính thường được gọi như sau:
- Google: Googlebot (thực tế là có đến 2 loại web crawlers trên Google là Googlebot Desktop dành cho tìm kiếm trên máy tính để bàn và Googlebot Mobile dành cho tìm kiếm trên thiết bị di động)
- Bing: Bingbot
- Yandex (công cụ tìm kiếm của Nga): Yandex Bot
- Baidu (công cụ tìm kiếm của Trung Quốc): Baidu Spider

Ngoài ra còn có nhiều bot crawlers ít phổ biến hơn, một số trong số đó không được liên kết với bất kỳ công cụ tìm kiếm nào nên tôi không liệt kê trong bài viết.
Tại sao việc quản lý bot lại quan trọng đến việc thu thập dữ liệu web?
Bot được phân chia thành 2 loại: bot độc hại và bot an toàn
Các con bot độc hại có thể gây ra rất nhiều thiệt hại từ trải nghiệm người dùng kém, sự cố máy chủ đến tình trạng đánh cắp dữ liệu.
Để chặn các bot độc hại này, hãy cho phép các con bot an toàn, chẳng hạn như web crawlers, truy cập vào các thuộc tính web.
Kết luận
Giờ thì bạn đã hiểu tầm quan trọng của web crawlers đến hoạt động cũng như thứ tự xếp hạng của trang web trên các công cụ tìm kiếm rồi nhỉ?
Nói chung, để có thể crawl được các dữ liệu trên trang web, bạn cần kiểm tra cấu trúc website có ổn định không? có trang nào hay toàn bộ website chặn quá trình thu thập dữ liệu không? Nội dung trang có đảm bảo để được index?
Hãy bắt tay chinh sửa để website luôn hoạt động hiệu quả nhất với bot các công cụ tìm kiếm nhé.
Chúc bạn thành công!
Bài viết liên quan:
- Domain Authority là gì? 9 Bước Check Domain Authority Checker khi tạo website
- 104 thuật ngữ SEO và định nghĩa bạn cần biết trong năm 2023
- Google Pagerank là gì? Cách tối ưu và Check Page Rank cho website
- Thuật toán Google Hummingbird là gì? Một số điều cơ bản bạn cần lưu ý